

Autores
Hace ya tiempo que el aprendizaje automático (o aprendizaje de las máquinas) se ha afianzado en todas las áreas de la actividad humana. No sólo desempeña un papel clave en el reconocimiento de voz, gestos, escritura e imágenes, sino que sin él es difícil imaginar la medicina moderna, la banca, la bioinformática y cualquier control de calidad. Hasta el pronóstico del tiempo se hace con ayuda de sistemas capaces de aprender y hacer generalizaciones por su propia cuenta.
En este artículo me adelanto a prevenir o disipar algunos de los conceptos erróneos asociados con el uso del aprendizaje automático en nuestro campo, la ciberseguridad.
Mito №1: “El aprendizaje automático en el campo de la seguridad informática es algo nuevo”
Por alguna razón, últimamente se ha empezado a hablar con una sospechosa frecuencia de la inteligencia artificial aplicada a la seguridad cibernética. Para el lector desprevenido, hasta podría parecer que se trata de una novedad.
Antecedentes históricos: en la década de 1950 se inventó uno de los primeros algoritmos de aprendizaje automático, una red neuronal artificial. Es curioso, pero en ese momento parecía que este algoritmo podría pronto crear una inteligencia artificial “fuerte”. Es decir, una capaz de pensar, de entenderse a sí misma y de resolver no sólo tareas preprogramadas. Su contraparte es una inteligencia artificial “débil”, que puede resolver algunas tareas creativas: reconocer imágenes, predecir el tiempo, jugar al ajedrez, etc. Ahora, después de 60 años, comprendemos que todavía falta mucho para crear una inteligencia artificial verdadera, y que lo que hoy se entiende como inteligencia artificial, en realidad es aprendizaje automático.

Fuente: http://www.gocomics.com/espanol/dilbert-en-espanol
Pues bien, en el campo de la ciberseguridad el aprendizaje automático no es nada nuevo. Los primeros algoritmos de esta clase se empezaron a implementar hace unos 10-12 años. En aquel entonces el número de nuevo malware se duplicaba cada dos años, y en algún momento se hizo evidente que para los analistas de virus no bastaba la simple automatización y era necesario un salto cualitativo. Éste vino con el procesamiento de todos los archivos disponibles en la colección de archivos de virus para poder buscar archivos similares a los ya analizados. Al principio, la decisión final sobre si un archivo era nocivo o no la tomaba un humano. Pero casi de inmediato esta función se confirió a un sistema robotizado.
En cualquier caso, no hay nada nuevo en el uso del aprendizaje automático en la ciberseguridad.
Mito №2: “El aprendizaje automático en la ciberseguridad es fácil porque ya todo está inventado”
Es cierto que para algunos campos de aplicación del aprendizaje automático sí existe una serie de algoritmos listos para usarse. Por ejemplo, en la búsqueda de caras de personas en fotos y su reconocimiento; el reconocimiento de emociones; la separación de imágenes de gatos y de perros y muchos otros casos, alguien ya usó su inteligencia para aislar características y regularidades, crear el aparato matemático pertinente, destinar recursos informáticos y después, compartir los frutos de su trabajo con el público. Y ahora cualquier colegial puede aplicar estos algoritmos.
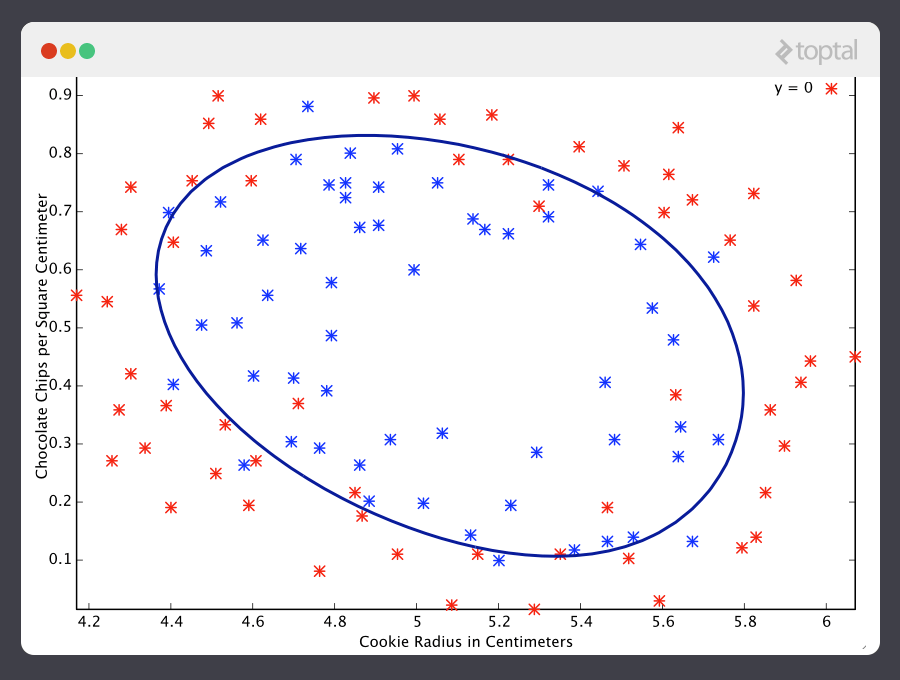
Por ejemplo, el aprendizaje automático puede usarse para determinar si la calidad las galletas corresponde a las normas de cantidad de chocolate y tamaño.
Fuente: http://simplyinsight.co/2016/04/26/an-introduction-to-machine-learning-theory-and-its-applications-a-visual-tutorial-with-examples/
Esto crea la falsa impresión de que también todo está listo para la tarea de detectar malware. Pero no es así. En Kaspersky Lab invertimos más de diez años para desarrollar y patentar una serie de tecnologías. Y seguimos trabajando para desarrollar las tecnologías existentes y desarrollar nuevas porque… lea el siguiente mito para saberlo:
Mito №3: “Basta con hacer una vez el aprendizaje automático y después se lo puede olvidar”
Hay una diferencia conceptual entre la detección de malware y la búsqueda de rostros de personas o gatos en las fotos. Las rostros son rostros hoy y lo siguen siendo mañana, nada cambia. En la gran mayoría de los campos de aplicación del aprendizaje automático la tarea no cambia con el tiempo. Pero en el caso de los programas nocivos, todo está en cambio constante y rápido . Y esto se debe a que los criminales son personas con una motivación específica (dinero, espionaje, terrorismo, etc.), su inteligencia no es artificial, prestan una resistencia activa y modifican a propósito los programas maliciosos para que estén fuera del modelo de aprendizaje automático.
Por lo tanto, el entrenamiento del sistema de aprendizaje automático tiene que ser constante, y a veces hasta es necesario repetir el entrenamiento a partir de cero. Obviamente, una solución de seguridad que no actualice su base antivirus será inútil frente a la rápida evolución del malware. Los criminales piensan de forma creativa cuando es necesario.
Mito №4: “Se puede permitir al software de seguridad que aprenda por su cuenta en el equipo del cliente”
Este mito supone que el software de seguridad puede ocuparse de procesar los archivos del cliente, que en su mayoría están limpios, pero que a veces son nocivos. Por supuesto, estos últimos pueden mutar, y al analizar las mutaciones el modelo puede aprender.
Pero esto no funciona en absoluto, ya que en el equipo de un cliente medio hay un número considerablemente menor de muestras de malware que el que reúnen los sistemas de recolección de virus de nuestro laboratorio antivirus. Y puesto que no hay muestras suficientes para el aprendizaje, no será posible hacer generalizaciones ni identificar regularidades. Es más, teniendo en cuenta la “creatividad” de los creadores de virus citada en la sección anterior, la detección puede no funcionar y el modelo simplemente comenzará a pensar que los archivos limpios son maliciosos y aprenderá en “dirección equivocada”.

Mito №5: “Se puede crear una solución de seguridad que use solo el aprendizaje automático, sin necesidad de utilizar otros métodos de detección”
Según este mito, no hace falta una protección multinivel basada en diferentes tecnologías, es mejor poner todos los huevos en una sola canasta, ya que es una canasta tan inteligente y avanzada. Un solo algoritmo es suficiente para todo.
Pero lo que en realidad pasa es lo siguiente. Una parte significativa del malware son familias que consisten en un gran número de variantes del mismo malware. Por ejemplo, Trojan-Ransom.Win32.Shade es una familia conformada por más de 50 000 programas maliciosos cifradores. Si existe un gran número de ejemplares, el modelo puede entrenarse y adquirir la capacidad de detectar amenazas en el futuro (dentro de ciertos límites, ver el tercer mito). El aprendizaje automático funciona muy bien.
Sin embargo, a menudo sucede que una familia consta de unas pocas muestras o de una sola. Esto indica que el autor no quiso iniciar una guerra con el software de protección: supongamos que el subsistema de detección por conducta detectó al virus desde el momento de su aparición, el autor se desistió, no quiso oponerle resistencia y decidió atacar solo a aquellos que no tienen software de seguridad instalado o que no cuentan con la detección de comportamiento (sí, los que pusieron todos los huevos en una canasta).
En tales “minifamilias” el modelo no se puede entrenar, porque el análisis de uno o dos ejemplares no se presta a generalizaciones (y esta es la esencia del aprendizaje automático). En este caso, es mucho más efectivo detectar la amenaza con métodos probados por el tiempo, por ejemplo mediante hash, máscaras, etc.
Otro ejemplo son los ataques selectivos. El autor de este tipo de ataque no hace “bombardeos en alfombra”, es decir, no produce cada vez más ejemplares de malware. Este autor crea un ejemplar para una víctima y, sin duda, esta copia no será detectada por la solución de protección (a menos que esté diseñada específicamente para este propósito, como por ejemplo, Kaspersky Anti-Targeted Attack Platform). En este caso, lo más rentable es la detección por hash.
Conclusión: es razonable utilizar diferentes herramientas en diferentes situaciones. La protección de varios niveles es más eficaz que la de un solo nivel. No vale la pena renunciar a algo eficaz sólo porque está “fuera de moda”.
Es el mismo problema de RoboCop
Y para terminar. Este no es un mito, sino más bien una advertencia. En la actualidad los investigadores están prestando cada vez más atención a los errores que cometen los sistemas complejos: en algunos casos, las decisiones que toman son imposibles de comprender desde el punto de vista de la lógica humana.
El aprendizaje automático es digno de confianza. Sin embargo, en los sistemas críticos (piloto automático de aviones y automóviles, medicina, control de trayectorias, etc.) hay normas de calidad muy estrictas que utilizan la verificación formal de programas, pero en el aprendizaje automático confiamos a una máquina parte de los pensamiento y de la responsabilidad. Por lo tanto, es imperativo que detrás del control de calidad del modelo estén expertos de renombre.
Índice
- Mito №1: “El aprendizaje automático en el campo de la seguridad informática es algo nuevo”
- Mito №2: “El aprendizaje automático en la ciberseguridad es fácil porque ya todo está inventado”
- Mito №3: “Basta con hacer una vez el aprendizaje automático y después se lo puede olvidar”
- Mito №4: “Se puede permitir al software de seguridad que aprenda por su cuenta en el equipo del cliente”
- Mito №5: “Se puede crear una solución de seguridad que use solo el aprendizaje automático, sin necesidad de utilizar otros métodos de detección”
- Es el mismo problema de RoboCop
De los mismos autores



En la misma categoría









Cinco mitos sobre el aprendizaje automático en el campo de la ciberseguridad