

Autores
La suplantación de DLL, o DLL Hijacking, es una técnica común en la que los atacantes sustituyen una biblioteca que ha sido invocada por un proceso legítimo por otra maliciosa La utilizan tanto los autores de malware de “destrucción masiva” (por ejemplo, de “stealers” y troyanos bancarios) como los grupos cibercriminales y de APT responsables de ataques selectivos. En los últimos años, el número de ataques de DLL Hijacking ha crecido de manera considerable.
Evolución del número de ataques que utilizan la técnica de DLL Hijacking. 2023 se considera el 100% (descargar)
Hemos visto esta técnica y sus diversas variantes, como el DLL Sideloading, en ataques dirigidos a organizaciones en Rusia, África, Corea del Sur y otros países y regiones del mundo. Con su ayuda se propaga Lumma, uno de los stealers más activos del año 2025. Los delincuentes que intentan beneficiarse de aplicaciones populares como DeepSeek también recurren al DLL Hijacking.
Detectar un ataque de DLL hijacking no es tan sencillo, porque la biblioteca se ejecuta en el espacio de direcciones de un proceso legítimo que confía en ella. Por lo tanto, para una solución de seguridad, su actividad puede tener la apariencia de la de un proceso confiable. Sin embargo, prestar demasiada atención al comportamiento de los procesos confiables puede tener un efecto negativo sobre el rendimiento general del sistema, y se debe buscar un delicado equilibrio entre la seguridad adecuada y la comodidad adecuada.
Detección de DLL Hijacking mediante un modelo de aprendizaje automático
Donde los algoritmos de detección simples no bastan, la inteligencia artificial puede ser de ayuda. Kaspersky lleva 20 años aplicando el aprendizaje automático para detectar actividad maliciosa en diferentes etapas. El Centro de especialización en IA investiga las posibilidades de varios modelos en el ámbito de la detección de amenazas y los entrena e implementa. Los colegas del centro de investigación de amenazas nos preguntaron si era posible detectar el DLL Hijacking mediante el aprendizaje automático y, lo más importante, si ayudaría a mejorar la precisión de la detección.
Preparación
Para entender si podemos enseñarle a un modelo a distinguir la carga de una biblioteca maliciosa de una legítima, primero debemos definir un conjunto de características que con alta probabilidad indiquen que hay un DLL Hijacking. Destacamos los siguientes indicadores clave:
- La biblioteca está donde no debe estar. Muchas bibliotecas estándar se encuentran en directorios estándar, mientras que una DLL suplantada a menudo está ubicada en una ruta inusual, por ejemplo, en la misma carpeta del archivo ejecutable que la llama.
- El archivo ejecutable está donde no debe estar. Los delincuentes a menudo guardan archivos ejecutables en rutas no estándar, como en el directorio temporal o en la carpeta del usuario, en lugar de hacerlo en %Program files%.
- Se cambió el nombre del archivo ejecutable. Para impedir que las detecten, los delincuentes a menudo guardan aplicaciones legítimas bajo nombres elegidos al azar.
- El tamaño de la biblioteca cambió y dejó de estar firmada.
- La estructura de la biblioteca cambió.
Dataset de entrenamiento y etiquetado
Como conjunto de datos (dataset) de entrenamiento, tomamos la información sobre las cargas de bibliotecas dinámicas. Estos datos se obtienen tanto de nuestros sistemas internos de procesamiento automático —por los que cada día pasan millones de archivos— como de la telemetría, incluida la que se proporciona con el consentimiento de los usuarios de las soluciones de Kaspersky de forma anonimizada a través de Kaspersky Security Network.
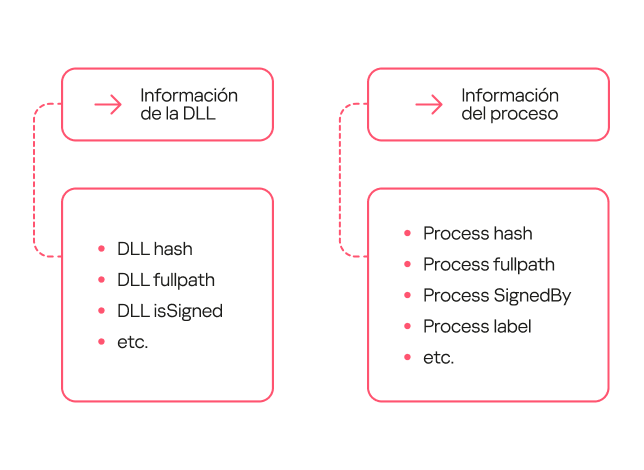
El etiquetado del conjunto de entrenamiento se realizó en tres iteraciones. Al principio, no teníamos la posibilidad de aplicar de forma automática las marcas de eventos asignadas por los analistas a la información sobre si el evento estaba relacionado con un ataque de DLL Hijacking. Tomamos como referencia los datos de nuestras bases de datos, que contienen la reputación de los archivos.
Realizamos todas las etiquetas posteriores por nuestra cuenta. Etiquetamos como DLL Hijacking los eventos de llamada a la biblioteca en los que el proceso era legítimo, y la DLL era maliciosa, ambos sin lugar a dudas. Sin embargo, tal etiquetado resultó ser insuficiente, ya que existen procesos, como svchost, cuya tarea principal es cargar varias bibliotecas. Como resultado, el modelo entrenado con estos datos mostró una alta tasa de falsos positivos y no era adecuado para su uso en la práctica.
En la siguiente iteración, filtramos además las bibliotecas maliciosas por familias, dejando en la categoría de DLL Hijacking solo aquellas que se comportaban de esa manera. El modelo entrenado con estos datos mostró una precisión mucho mayor y confirmó la hipótesis de que es posible detectar ataques de este tipo mediante el aprendizaje automático.
En esta etapa, el dataset de entrenamiento ya contaba con varios millones de objetos, entre los cuales alrededor de 20 millones eran archivos limpios y unos 50 mil eran maliciosos.
| Estado | Total | Archivos únicos |
| Desconocido | ~ 18 millones | ~ 6 millones |
| Malicioso | ~ 50 mil | ~ 1000 |
| Limpio | ~ 20 millones | ~ 250 mil |
Los modelos posteriores se entrenaron con los resultados generados por sus predecesores, que fueron verificados y etiquetados adicionalmente por analistas. Esto nos permitió aumentar de forma considerable la eficacia del entrenamiento.
Carga de bibliotecas DLL: así luce cuando es normal
Supongamos que tenemos una muestra etiquetada que contiene una gran cantidad de eventos de carga de bibliotecas realizadas por diferentes procesos. ¿Cómo podemos describir una biblioteca “limpia”? Si utilizamos la combinación “nombre del proceso + nombre de la biblioteca”, no estaremos tomando en cuenta los procesos que cambiaron de nombre. Y este cambio de nombre puede hacerlo no solo un atacante, sino también un usuario legítimo. Si en lugar del nombre del proceso usamos su hash, resolveremos el problema de los cambios de nombre, pero entonces cada versión de una biblioteca se considerará como una biblioteca separada. Así que decidimos usar la combinación “nombre de la biblioteca + firma del proceso”. Aunque con esta opción consideraremos como una sola biblioteca todas las que tengan el mismo nombre de un mismo proveedor, en conjunto esta combinación ofrece una imagen bastante realista.
A su vez, para describir eventos seguros de carga de bibliotecas utilizamos un conjunto de contadores que incluían información sobre los procesos (como la frecuencia con la que aparece un nombre de proceso específico asociado a un archivo con un mismo hash o la frecuencia de aparición de una ruta concreta para un archivo con ese mismo hash, entre otros datos); información sobre las bibliotecas (como la frecuencia de aparición de una ruta determinada para esa biblioteca o la proporción de ejecuciones legítimas, entre otros aspectos); así como propiedades de los eventos, por ejemplo, si la biblioteca se encuentra en el mismo directorio que el archivo que la invoca.
Como resultado, obtuvimos un sistema con múltiples agregados (conjuntos de contadores y claves), con los que se puede describir el evento de carga. Los agregados pueden contener una clave (por ejemplo, el hash de una DLL) o varias (por ejemplo, el hash de un proceso + la firma del proceso). A partir de estos agregados, podemos obtener un conjunto de características que describen el evento de carga de la biblioteca. En el esquema a continuación se presentan ejemplos de cómo se obtienen tales características:
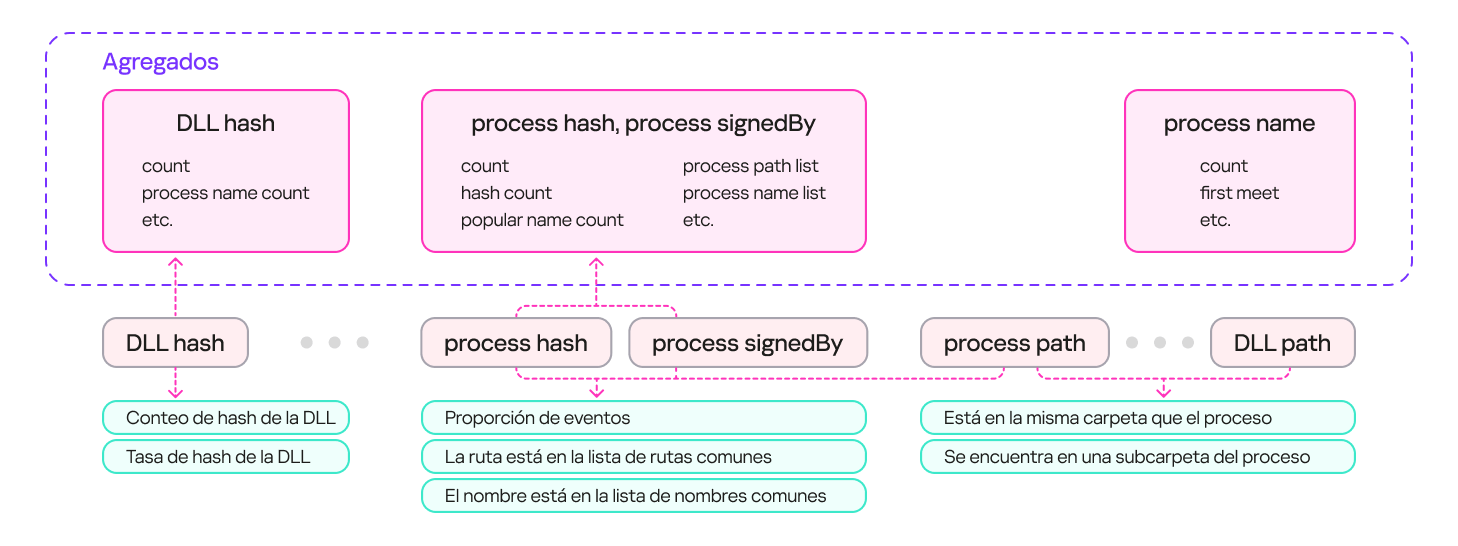
Obtención de características de agregados
Carga de bibliotecas DLL: cómo describir el Hijacking
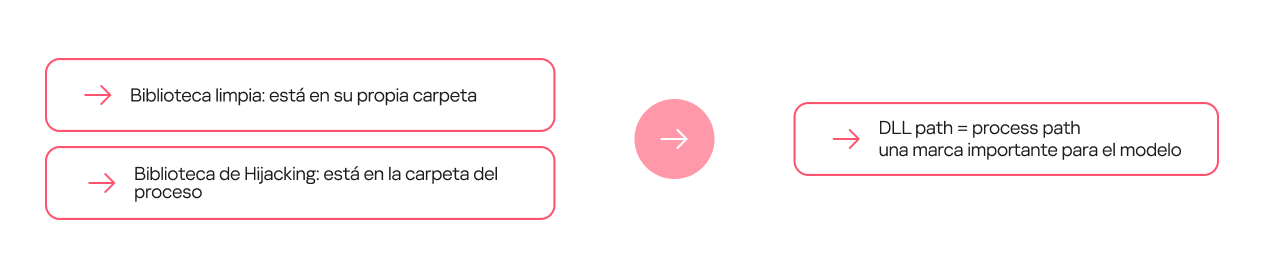
Algunas combinaciones de indicadores (o dependencias) apuntan con alta probabilidad a un caso de DLL Hijacking. Se puede tratar de dependencias simples. Por ejemplo, en algunos procesos, la biblioteca limpia que se invoca siempre se encuentra en una carpeta separada, mientras que la maliciosa a menudo se coloca en la carpeta del proceso.
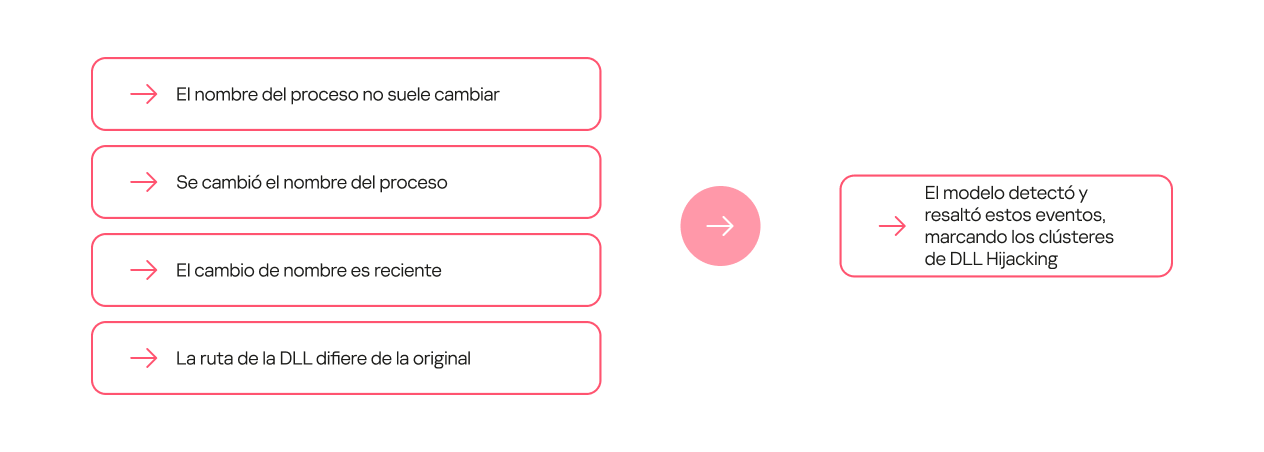
Otras dependencias pueden ser más complejas y requerir que se cumplan varias condiciones. Por ejemplo, el simple cambio de nombre de un proceso no indica por sí mismo un DLL Hijacking, pero si este nuevo nombre aparece por primera vez en el flujo de datos y la biblioteca se encuentra en una ruta no estándar, es muy probable que sea maliciosa.
Evolución de los modelos
En el marco del proyecto, entrenamos varias generaciones de modelos. La tarea principal de la primera generación fue demostrar que, en principio, el aprendizaje automático se puede aplicar para detectar el secuestro de DLL. Al entrenar este modelo, utilizamos la interpretación más amplia del término.
El esquema de trabajo del modelo era lo más sencillo posible:
- Tomamos un flujo de datos y extraemos de él una descripción de frecuencia para conjuntos seleccionados de claves.
- Tomamos el mismo flujo de datos de otro período de tiempo y obtenemos un conjunto de características.
- Aplicamos el etiquetado de tipo 1, donde están marcados como DLL Hijacking aquellos eventos en los que un proceso legítimo cargaba una biblioteca maliciosa perteneciente a un conjunto específico de familias.
- Entrenamos el modelo con los datos obtenidos.
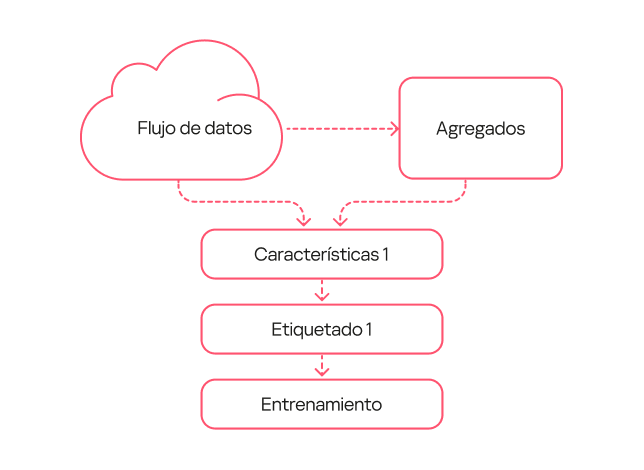
Esquema de funcionamiento del modelo de primera generación
El modelo de segunda generación se entrenó con datos procesados por el modelo de primera generación y verificados por analistas (etiquetado tipo 2). Como resultado, el etiquetado fue más preciso que durante el entrenamiento del primer modelo. Además, en la descripción de las descargas de bibliotecas, añadimos características adicionales que describen la estructura de la biblioteca y aumentamos un poco la complejidad del esquema.
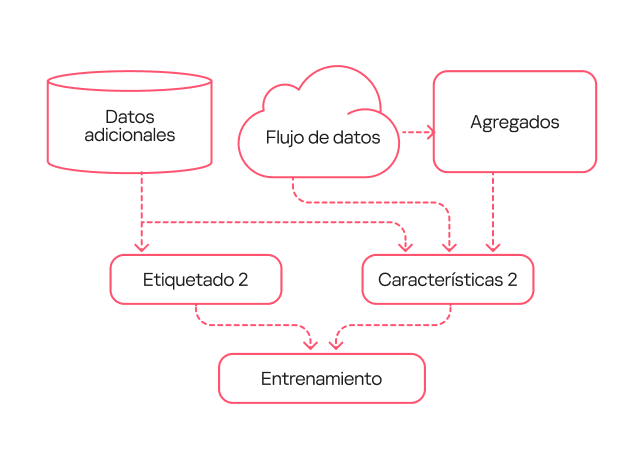
Esquema de funcionamiento del modelo de segunda generación
Gracias a los resultados del trabajo de este modelo de segunda generación, pudimos identificar varios tipos comunes de falsos positivos. Por ejemplo, en la clasificación se incluyeron aplicaciones potencialmente no deseadas, que en cierto contexto pueden comportarse de forma similar a DLL Hijacking, pero que en la mayoría de los casos no pertenecen a este tipo de ataque y no son maliciosas.
En el modelo de tercera generación trabajamos sobre los errores. En primer lugar, con la ayuda de los analistas, en el conjunto de datos de entrenamiento marcaron las aplicaciones potencialmente no deseadas para que el modelo no las detectara. En segundo lugar, en la nueva versión se utilizó un marcado ampliado que contiene detecciones útiles de primera y segunda generación. Además, ampliamos la descripción de características mediante one-hot encoding (una técnica de transformación de características categóricas en formato binario) para ciertos campos. Además, como con el paso del tiempo el volumen de eventos procesados por el modelo fue creciendo, en esta versión añadimos la normalización de todos los indicadores en función del tamaño del flujo de datos.
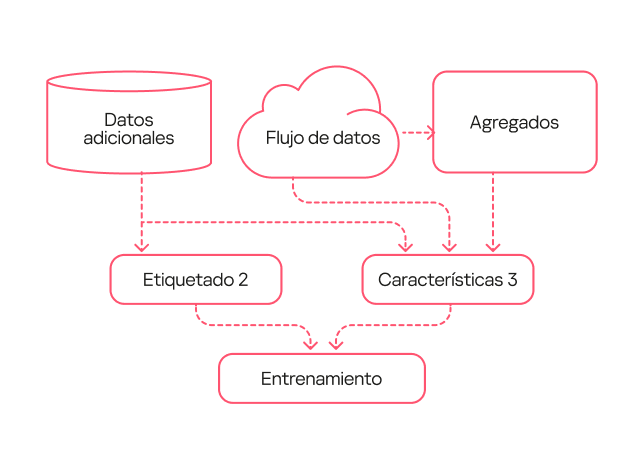
Esquema de funcionamiento del modelo de tercera generación
Comparación de modelos
Para evaluar el desarrollo de nuestros modelos, los usamos para procesar datos de prueba con los que ninguno de ellos había trabajado antes. En el siguiente gráfico se puede ver la relación entre los verdaderos positivos y los falsos positivos de cada modelo.
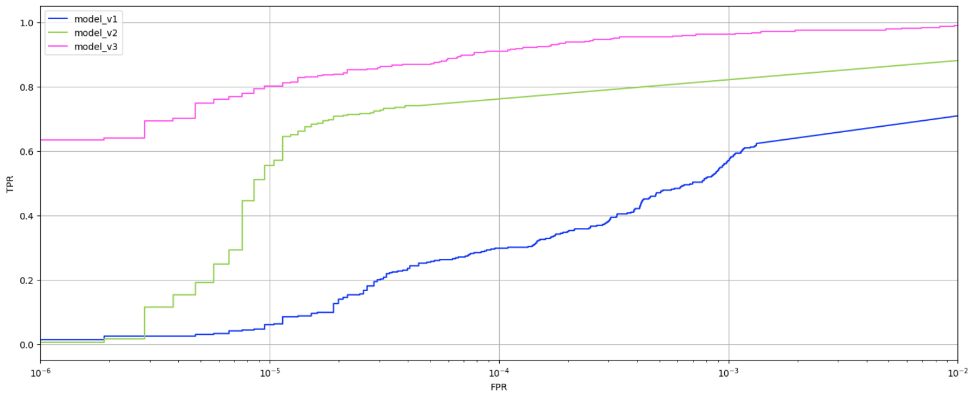
Dinámica del número de verdaderos positivos y falsos positivos de los modelos de primera, segunda y tercera generación
A medida que los modelos se iban desarrollando, aumentaba la proporción de verdaderos positivos: si la primera generación ofrecía un resultado que no estaba mal (0,6 o más), pero con una alta proporción (10–3 o más) de falsos positivos, en la segunda ya era de 10–5, y la tercera generación con la misma proporción de falsos positivos ofrece 0.8 verdaderos positivos, lo que ya puede considerarse un buen resultado.
Si evaluamos los modelos en un flujo con una puntuación fija, notaremos que el número absoluto de nuevos eventos marcados como DLL Hijacking ha ido creciendo de generación en generación. Si evaluamos los modelos por la proporción de veredictos incorrectos, también se observa el progreso: el primer modelo se equivoca con bastante frecuencia, mientras que el segundo y el tercero lo hacen mucho menos.
Porcentaje de errores en los resultados del trabajo de los modelos, julio de 2024 – agosto de 2025 (descargar)
Aplicación práctica de los modelos
Usamos las tres generaciones de modelos en nuestros sistemas internos para buscar posibles casos de DLL Hijacking en los flujos de datos de telemetría. Cada día ingresan a nuestro sistema 6,5 millones de eventos de seguridad vinculados a 800 mil archivos únicos. A partir de este conjunto de datos, en cada periodo establecido se elaboran agregados que luego se enriquecen y se cargan en los modelos. Clasificamos los datos de salida según el modelo y la probabilidad de DLL Hijacking que haya asignado al evento, y se los entregamos a los analistas. Así, si el tercer modelo califica con un alto grado de certeza un evento como DLL Hijacking, entonces hay que revisarlo con prioridad, mientras que el veredicto menos claro del primer modelo debe revisarse al final.
De forma paralela, se prueban los modelos en un flujo de datos de prueba con los que todavía no hayan trabajado. Esto se hace para evaluar cómo cambia la eficacia: con el tiempo, las detecciones del modelo pueden bajar su precisión. En el gráfico de abajo se puede ver que la proporción de detecciones correctas varía un poco con el tiempo, sin embargo, en promedio, los modelos identifican entre el 70% y el 80% de los casos de DLL Hijacking.
Evolución de la eficiencia de los modelos (datos sobre el funcionamiento de las tres generaciones), octubre de 2024 – septiembre de 2025 (descargar)
Además, hace poco implementamos un modelo para detectar DLL Hijacking en la plataforma Kaspersky SIEM, después de haberlo probado en el servicio Kaspersky MDR. Durante la fase piloto, el modelo ayudó a detectar y prevenir una serie de incidentes relacionados con el DLL Hijacking en los sistemas de nuestros clientes. Hemos publicado un artículo aparte sobre cómo funciona en nuestra solución Kaspersky SIEM el modelo de aprendizaje automático para la detección de ataques selectivos que se lanzan mediante la técnica de DLL Hijacking y qué incidentes ha detectado.
Conclusión
Como resultado del aprendizaje y la aplicación de tres generaciones de modelos, podemos afirmar que el experimento de detección de DLL Hijacking mediante el uso de aprendizaje automático fue exitoso. Logramos desarrollar un modelo capaz de diferenciar los eventos similares a DLL Hijacking de otros tipos de eventos y lo llevamos a un estado apto para su uso práctico, no solo en nuestros sistemas internos, sino también en productos comerciales. En este momento, los modelos funcionan en la nube, examinan cientos de miles de archivos únicos y detectan miles de archivos utilizados en ataques de tipo DLL Hijacking, identificando cada tanto variantes aún desconocidas de este tipo de ataques. Los resultados del trabajo de los modelos se remiten a los analistas, quienes los verifican y generan nuevas firmas de malware a partir de ellos.









Cómo enseñamos a un modelo de ML a detectar DLL Hijacking